
Statistical significance is where many German A/B testing programs fail. Tests stopped too early, p-values misinterpreted, sample sizes ignored. The result: false-positive winners that don’t reproduce when implemented. Real CRO requires statistical discipline — without it, you’re running tests but making decisions on noise.
This guide walks through what statistical significance A/B testing in Germany actually means in 2026: p-values explained in plain language, sample size methodology, confidence intervals, common mistakes, and pragmatic guidelines.
For broader A/B testing see our A/B testing Germany guide.
What is statistical significance?
Plain language explanation:
The question
If we run a test and Variant B converts higher than Variant A, is it because Variant B is genuinely better, or just random chance?
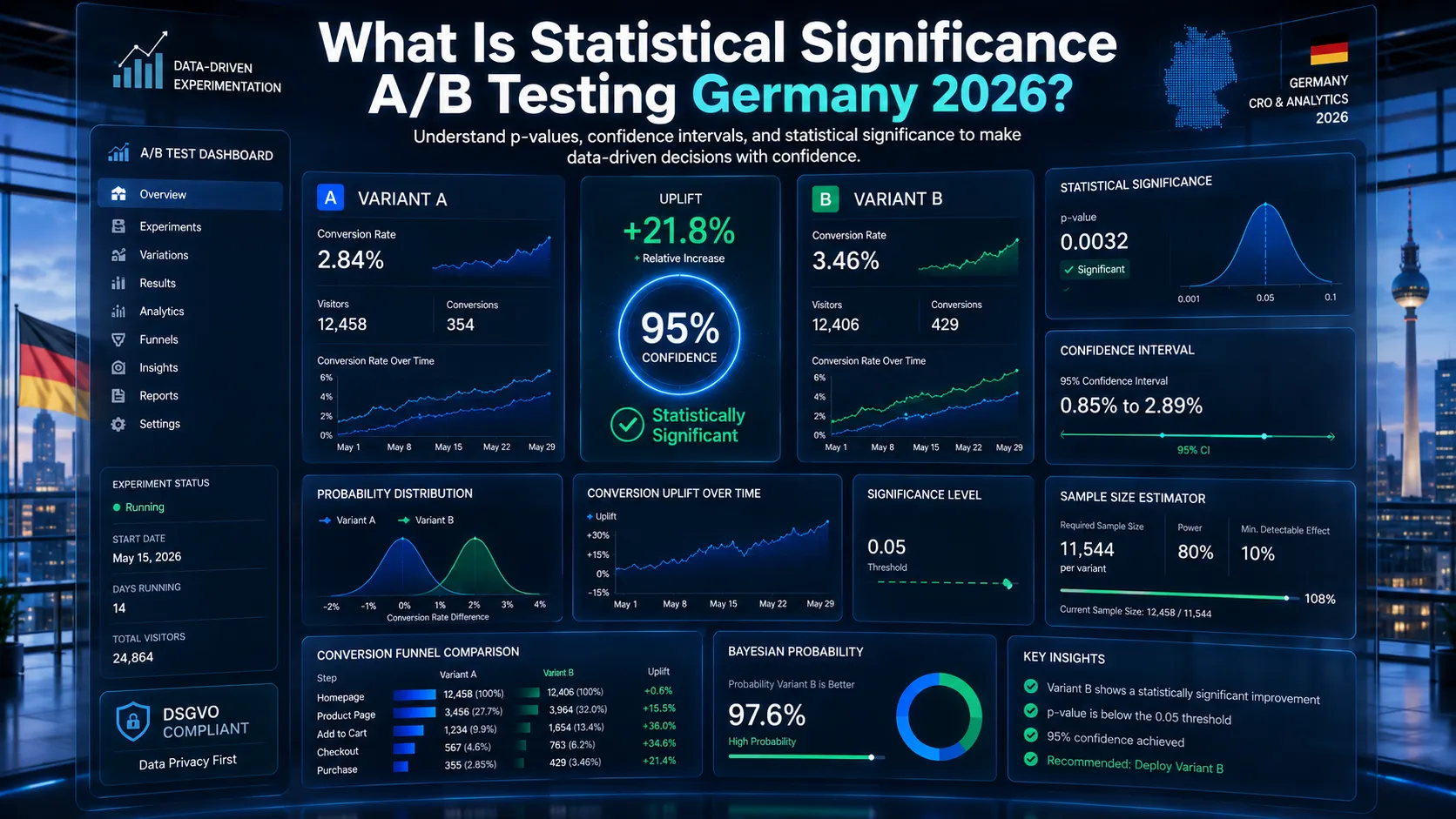
Statistical significance
Probability that the difference is real, not random.
Standard threshold
p < 0.05 = 5% chance the result is random. 95% confidence the result is real.
Practical interpretation
p < 0.05: declare winner with reasonable confidence. p > 0.05: result not statistically significant. Don’t make decisions on it.
What’s a p-value?
The most-misunderstood statistic in A/B testing:
Definition
p-value = probability of observing this result (or more extreme) if there’s actually no difference between variants.
Simpler version
How likely is it that random chance produced this result?
Examples
- p = 0.04: 4% chance random chance produced this difference. Likely real.
- p = 0.50: 50% chance random chance. Inconclusive.
- p = 0.001: 0.1% chance random. Very strong signal.
Common misinterpretations
- “p = 0.04 means there’s a 96% chance Variant B is better.” → WRONG
- “p = 0.04 means there’s a 4% chance the result is wrong.” → WRONG
p-value tells you about likelihood of result under null hypothesis. Not directly about likelihood of true effect.
What’s a confidence interval?
The range of plausible true effects:
Example
Test shows Variant B has 15% higher conversion. 95% confidence interval: 5% to 25% lift.
Interpretation
True lift is somewhere between 5% and 25%, with 95% confidence.
Why this matters
A “winning” test with confidence interval -5% to +25% means true effect could be negative. Not actually a clear winner.
Better than p-value alone
Confidence interval shows uncertainty. p-value just says “significant or not.”
How do you calculate sample size?
Three inputs needed:
Current conversion rate
Baseline. Example: 2.5%.
Minimum detectable effec
Smallest meaningful improvement. Example: 10% relative lift = improvement to 2.75%.
Statistical power
Probability test detects real effect if it exists. Typically 80%.
Plus confidence level
Typically 95%.
Sample size formula
Online calculators (Evan Miller, Optimizely, VWO). Plug in inputs.
Example calculation
Baseline 2.5%, minimum effect 10% relative, 95% confidence, 80% power = ~30,000 visitors per variant.
What sample size makes A/B testing viable?
Small site (under 100k monthly visitors)
Realistic minimum effect detectable: 20–30%. Test bigger changes.
Mid-size (100k–500k monthly visitors)
10–20% effects detectable.
Large (500k+ monthly visitors)
5–15% effects detectable.
Implications
Low-traffic sites need to test bigger changes. “Move CTA 10px” likely won’t show significance.
How long should tests run?
Two requirements:
Statistical sample size reached
Don’t stop before sample size hit.
Minimum time for cycle coverage
- Full week (weekday + weekend)
- B2B: full business week
- Includes business cycle (e.g., monthly sales cycle if relevant)
Maximum
6 weeks before external factors introduce noise. Holiday seasons especially disruptive
Practical rule
For typical German mid-size sites: 2–4 weeks per test.
What are common statistical mistakes?
Seven mistakes:
Stopping tests early
“Variant B at 95% confidence after 3 days!” Often false positive. Wait for sample size.
p-hacking
Looking at 20 metrics, reporting whichever hits significance. Bonferroni correction needed.
Ignoring sample size
Declaring winner with 100 visitors per variant. Not enough data.
Misinterpreting non-significant as “no difference”
Non-significant means inconclusive, not “no effect.”
Cherry-picking segments
“Test failed overall, but it won for mobile Berlin users!” Statistical fishing.
Multiple comparison problem
Running 50 tests. 5% false positive rate × 50 tests = 2-3 false winners expected. Adjust significance threshold.
Confusing statistical with practical significance
5% lift is statistically significant but if conversion impact is €100/year, who cares.
What’s the Bayesian vs Frequentist debate?
Two statistical approaches:
Frequentist (traditional)
p-values, significance thresholds. Standard in most testing tools.
Bayesian
Calculates probability variant is better. Continuously updates as data comes in.
Frequentist pros
Well-understood. Industry standard. Most tools support.
Bayesian pros
Intuitive output (“87% chance Variant B is better”). Can peek at results without statistical penalty.
In 2026
Most testing tools offer both. Choose based on team familiarity + statistical preference.
For most German businesses: frequentist (95% confidence p < 0.05) is standard, well-supported.
How does German market affect statistical considerations?
Three factors:
Lower conversion rates
German market lower CR than US for same products = larger sample size needed to detect same effect.
Cookie banner sample bias
Users who reject all cookies may not be tracked. Sample bias possible. Document + adjust.
Cross-device tracking limitations
DSGVO + browser tracking restrictions = harder to track users across devices. Some test contamination possible.
What statistical tools do testing platforms provide?
Built-in significance calculators
VWO, Optimizely, Convert all calculate p-values + significance automatically.
Sample size calculator
Most platforms include. Some external (Evan Miller widely used).
Bayesian options
Increasingly available. Optional in most platforms.
Confidence intervals
Modern platforms show. Use them, don’t just look at p-values.
What statistical literacy do CRO teams need?
Five concepts to master:
Statistical significance
p-values, confidence levels, what they mean.
Sample size
How to calculate, why it matters.
Effect size
Practical vs. statistical significance.
Multiple comparison
Bonferroni, FDR, why testing many things needs adjustment.
Confidence intervals
Range of likely true effects.
Without these: random testing producing random “winners.”
Frequently asked questions about statistical significance A/B testing
Probability that observed result happened by random chance. p < 0.05 = significant.
95% standard. 99% for high-stakes. Do not go below 90%.
Online calculators. Inputs: current CR, minimum effect, confidence, power.
No. Stopping early dramatically increases false positive rate. Wait for sample size.
Looking at many metrics + reporting whichever hits significance. Adjust for multiple comparisons.
Frequentist standard. Bayesian intuitive. Most tools offer both. Pick what your team understands.
Run longer for more data, or accept it as inconclusive. Do not force interpretation.
Statistical = result is real. Practical = result matters to business. Both required for meaningful change.
Need help with A/B test statistics?
If you’re setting up testing methodology for your German business and want a 30-minute scoping conversation about statistical rigor + sample sizing, book a meeting or send details via our contact page.